Retrieval-Augmented Generation: A High-Level Overview
by Yustyna Klish, Consultant
Retrieval-Augmented Generation: A High-Level Overview
In the rapidly evolving landscape of artificial intelligence, Retrieval-Augmented Generation (RAG) stands out as a groundbreaking approach to enhancing the capabilities of language models. By integrating information retrieval with advanced generation techniques, RAG systems can provide more accurate, contextually relevant, and informative responses. This article provides a high-level overview of RAG, delving into its architectural principles, the role of word embeddings and vector stores, and the process of preparing and managing data.
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) combines two key components: information retrieval and language generation. In essence, a RAG system retrieves relevant documents or snippets from a vast repository of information and uses them to augment the input to a language model, enhancing its ability to generate precise and contextually relevant responses.
Think of RAG as a more resourceful student in an open book exam, compared to a standard LLM which is like a student relying solely on memory in a closed book exam. RAG can look up information as needed, providing more accurate and contextually relevant answers, especially when dealing with specialized or proprietary data.
Speaker Highlight
Fine-tuning a model is like a student studying for a closed book exam. They learn what they can and try remember the answers when faced with a question. RAG is a student sitting an open book exam. They can look up the information they need to answer a question.
Key Components of RAG:
Creating a RAG comprises of the following core steps:
- Data Loading
- Data Cleaning and Chunking
- Document Embedding
- Document Retrieval
- Response Generation with a LLM
At a high level, the RAG architecture resembles something like this:
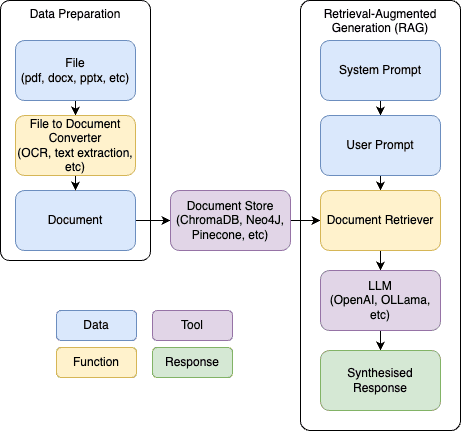
Data Loading:
The first step in creating a RAG is data collection, which can involve:
- Downloading files from Sharepoint or Google Drive
- Scraping websites using tools like BeautifulSoup
- Manually downloading PDFs
- Connecting to databases
- Integrating APIs
Fortunately, in Python land we have several libraries at our disposal that make quick work of extracting text from many of the most common file types. I've recently had some good success with Unstructured, which worked well for me out-of-the-box.
Data cleaning and chunking:
I may have lied about data loading working well out-of-the-box. The text I had extracted had many special characters, line breaks, white spaces, broken paragraphs, headers/footers, and awkward breaks separating paragraphs that semantically belonged together. Using this data as-is would lead to problems with retrieving the most relevant documents, not giving the LLM the best material from which it would generate a response.
This is a common enough problem in the world of data science that many libraries exist to clean up extracted text and make sure documents are broken down in semantically coherent ways.
While this article won't go into the details of chunking, it's worth mentioning that documents can be broken down by title, section, page, or semantic unit. Breaking a document down into chunks reduces the amount of tokens that will then get embedded and fed into the LLM. When chunking a document, it's worth considering the following:
- Will your chunked text fit inside the context window of your LLM?
- Will each chunk be large enough to contain all relevant information for that section?
- Will your chunks overlap with other chunks so they are aware of their surrounding context?
This is also the time to add any metadata to your documents - things like the file name, page number, author, file location, AI generated classifications or any other metadata that may come in handy in later steps.
Embeddings and Vector Stores:
A core component of RAG involves transforming text into numeric vectors that encode semantic meaning. Word embeddings capture the relationships between words in a vector space. As a simplification, words that are close semantically will be embedded as vectors that are close in the vector space (whether this is a cosine similarity or Euclidean distance or some other metric).
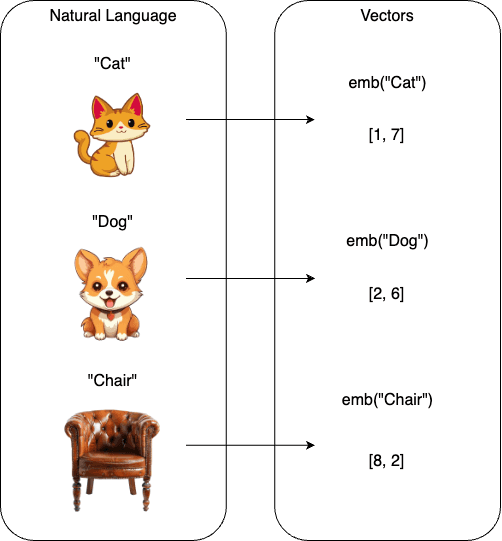
Many different embedding models exist, such as SentenceTransformers (356-dimensional vectors) or OpenAI models (1536-dimensional vectors for text-embedding-3-small or 3072 for text-embedding-3-large). Larger sized vectors typically can encode more information at the cost of performance, and it's worth considering whether dimensionality reduction techniques are relevant for your use-cases. Whatever route you go down, remember that in general, the embedding model used to embed your documents must be the same as that used to embed user questions.
With all the cleaned and chunked documents from the previous step, and an embedding model chosen, embed these documents into a vector database of your choosing. The specifics here depend on your platform - Databricks, Postgres and MongoDB come with a vector store. I personally like ChromaDB as a free and open source vector database I can set up and run locally.
Document Retrieval:
By this stage you should have all of the documents you want to use cleaned up and embedded in your vector database. We are now ready to put it to use.
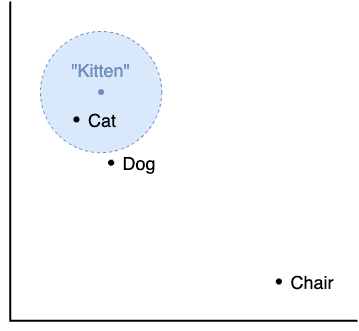
When a user asks a question like "What is a kitten?", we want to retrieve all documents we have that encode the meaning of this question. The first step is to embed the user question into a vector using the same embedding model used to embed our documents. We then query our vector database and ask it to retrieve the nearest vectors that match our question embedding. While we may not have something that exactly matches the embedding of "What is a kitten?", we may have semantically similar documents embedded explaining what a cat is, or what a puppy is. These closest matching documents will be retrieved from our vector database and will be the supplementary context we feed into our LLM to answer the user's question.
Generating Responses with an LLM:
Once the relevant documents are retrieved, they are used to augment the input to the language model to generate a response. The core idea here is to use a prompt template and pass in the user question and our retrieved documents as context, to create a prompt that gets passed to the LLM. This can be accomplished pretty well with tools like Langchain and their PromptTemplate module.
At its core level, your code may look something like this:
rag_prompt_template = """
Answer the following question: {question}. Keep in mind the following context in your response: {context}
"""
rag_prompt = PromptTemplate(
input_variables=["question", "context"],
template=rag_prompt_template
)When we pass in the user's question and context, the final prompt we feed into our LLM may look something like this:
Answer the following question: "What is a kitten?". Keep in mind the following context in your response: "A cat is a small carnivorous mammal often kept as a house pet", "A kitten is a baby cat".
What we get back from the LLM is a response which has been augmented by the retrieval of relevant documents, hence the name retrieval augmented generation.
The following code outlines the core functionality of the RAG - querying a vector database which stores our documents, and using an llm to generate a response.
# Function used to query the vector database and retrieve relevant documents
def query_collection(collection, query_texts, n_results) -> dict:
print(f"Querying collection...")
results = collection.query(
query_texts = query_texts,
n_results = n_results,
include=["documents", "metadatas", "distances"]
)
return results
#Function used to get the LLM response
def get_llm_response(question:str, context:str):
llm = ChatOpenAI(
model="gpt-4o-mini"
)
rag_prompt_template = """Answer the following question: {question}. Keep in mind the following context in your response: {context}
"""
rag_prompt = PromptTemplate(
input_variables=["question", "context"],
template=rag_prompt_template
)
llm_chain = rag_prompt | llm
response = llm_chain.invoke({"question": question, "context": context})
return response.content
# Tying the retrieved documents from a user question to the LLM generation function
user_prompt = "What is a kitten?"
documents = query_collection(collection, user_prompt, n_results=docs_to_retrieve)
context = ["\n\n".join(document) for document in documents["documents"]][0]
llm_response = get_llm_response(user_prompt, context)
print(llm_response)
Conclusion
This overview highlights the core concepts and components of RAG. By leveraging the strengths of information retrieval and language generation, RAG produces highly relevant and contextually accurate responses. Its simplicity and cost-effectiveness make it a valuable tool in the growing field of Generative AI.