Unit testing in DBT
by Yash Mehta, Consultant
dbt 1.8.0 introduced many cool features, with one of them being unit testing! Unit testing plays a crucial role for several reasons:
- Data Quality Assurance: Ensuring that transformations and data processing steps produce the correct results is essential for maintaining high data quality. Unit tests can validate that the logic applied to the data yields the expected outcomes.
- Early Error Detection: Data pipelines can be complex, involving multiple transformations and dependencies. Unit tests can catch errors in individual transformations early, before they propagate through the pipeline and cause larger issues.
- Confidence in Changes: As data models evolve and new features are added, unit tests provide confidence that existing functionality continues to work as expected. This is particularly important in a collaborative environment where multiple team members may be working on the same pipeline.
Simplified Maintenance: With unit tests in place, maintaining and updating data pipelines becomes easier. Tests ensure that changes do not break existing functionality, making the codebase more robust and maintainable.
Regression Prevention: Unit tests help prevent regressions by ensuring that new changes do not negatively impact existing functionality. This is critical in data pipelines where accurate and consistent data processing is required.
For more information about the release, visit https://docs.getdbt.com/docs/dbt-versions/core-upgrade/upgrading-to-v1.8

When to use unit tests
Unit testing models is a good practice to ensure that the pipelines are robust and changes do not break the transformation logic. But, to start with, unit tests should be applied when:
Testing complex and/or custom logic Covering edge cases for models Developing critical models that have downstream impact https://docs.getdbt.com/docs/build/unit-tests#when-to-add-a-unit-test-to-your-model
Creating a unit test
To create a unit test, you need a YML file inside the models folder. Fixtures (In software testing, fixtures are sets of conditions or inputs that are used to test software. They provide a known good state against which the tests can be run) need to reference the file name only, not the full path, or {filename}.csv. By default, dbt will scan the entire tests/fixtures folder to find the filename that is being used in the test. Inputs and output can be of 3 formats
- CSV — comma separated values
- SQL — does not fetch data using SQL for unit testing. Written as select statements with union.
- Row — dictionary format
Only the referenced columns need to be provided in these files. For example a source has 20 columns, but if the model being unit tested only uses 3 columns, then the input file only need these 3 columns. This makes setting up the tests very easy.
For this article, we will use Jaffle shop data and convert the seed files as source by loading them first. This change will help demonstrate how to mock data for source as well.
version: 2
unit_tests:
- name: unit_test_stg_payments
model: stg_payments
given:
- input: source('jaffle_shop_raw', 'raw_payments')
format: csv
fixture: stg_payments_input
expect:
format: csv
fixture: stg_payments_expect
- name: unit_test_orders
model: orders
given:
- input: ref('stg_orders')
format: csv
fixture: orders_stg_orders_input
- input: ref('stg_payments')
format: csv
fixture: stg_payments_expect
expect:
format: csv
fixture: orders_expectOrganising test files
It is more convenient to pass the input and output as CSV files instead of rows or SQL format. So, we need to ensure that we save the files in an organised location where its easy to find the relevant files. Each file in the fixtures flag need to be stored in tests/fixtures/ folder.
Given that there are a large number of models in real work scenarios, it is better to organise the files as subfolders inside fixtures. Note that each file name needs to be unique but you can reuse them amongst unit tests — if required. These files can be referenced in the unit tests under fixtures.
Running the unit tests
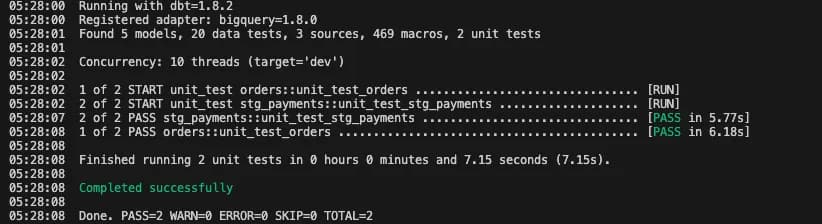
Unit tests get triggered when executing dbt test or build command. To separate unit test execution from data test, you need to run the following command:
dbt test --select "test_type:unit"A successful run looks like this:
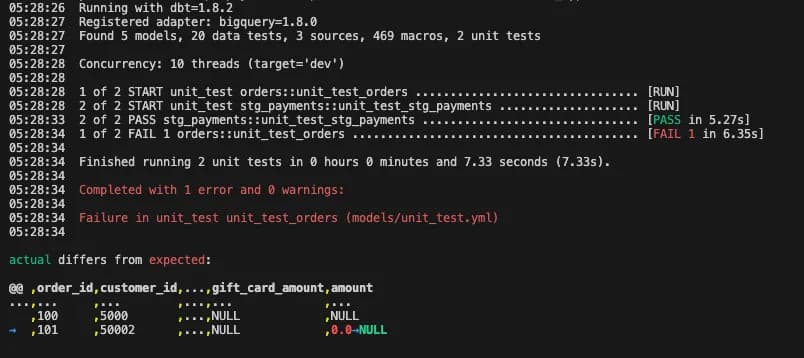
But, when a unit test fails, dbt will show what values do not match the expected output. In the following example, you can see that dbt was expecting 0 instead of NULL.
Automating unit testing inside your CI/CD pipelines
By default, dbt build command will run the unit tests as well. So, if your existing pipelines use dbt build command, then any unit tests that have been added will be executed too. The quickest way is to exclude unit tests from the build command. This command will ensure that unit tests are excluded from ongoing dbt runs
dbt build <existing flags> --exclude "test_type:unit"Unit tests are a way to identify the errors early, so they should be executed on CI/CD pipelines to ensure that the changes do not break existing models or the new models are tested appropriately. As shown in the flow below, the container build step should only be executed after all the unit test pass. This command to run all the unit tests is:
dbt test --select "test_type:unit"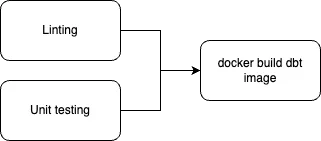
Features I hope are added in the future
- Unit testing coverage
- Ability to provide a full path to the file for the fixture
- Ability to test dependent models together. While simple models are easy to test, models with intricate logic or multiple dependencies might require extensive setup and maintenance of test fixtures.
- More documentation and community support.
Summary
Unit testing in dbt is crucial for ensuring data quality, early error detection, confidence in changes, simplified maintenance, and regression prevention. It helps validate that transformations produce the correct results, catch errors early, and maintain high data quality. Now, with unit testing being native to dbt, it becomes much more convenient to setup new tests and maintain the code base.
Reach out to us if we can help you in setting up dbt for your organisation, or implementing best practices for your data pipelines.